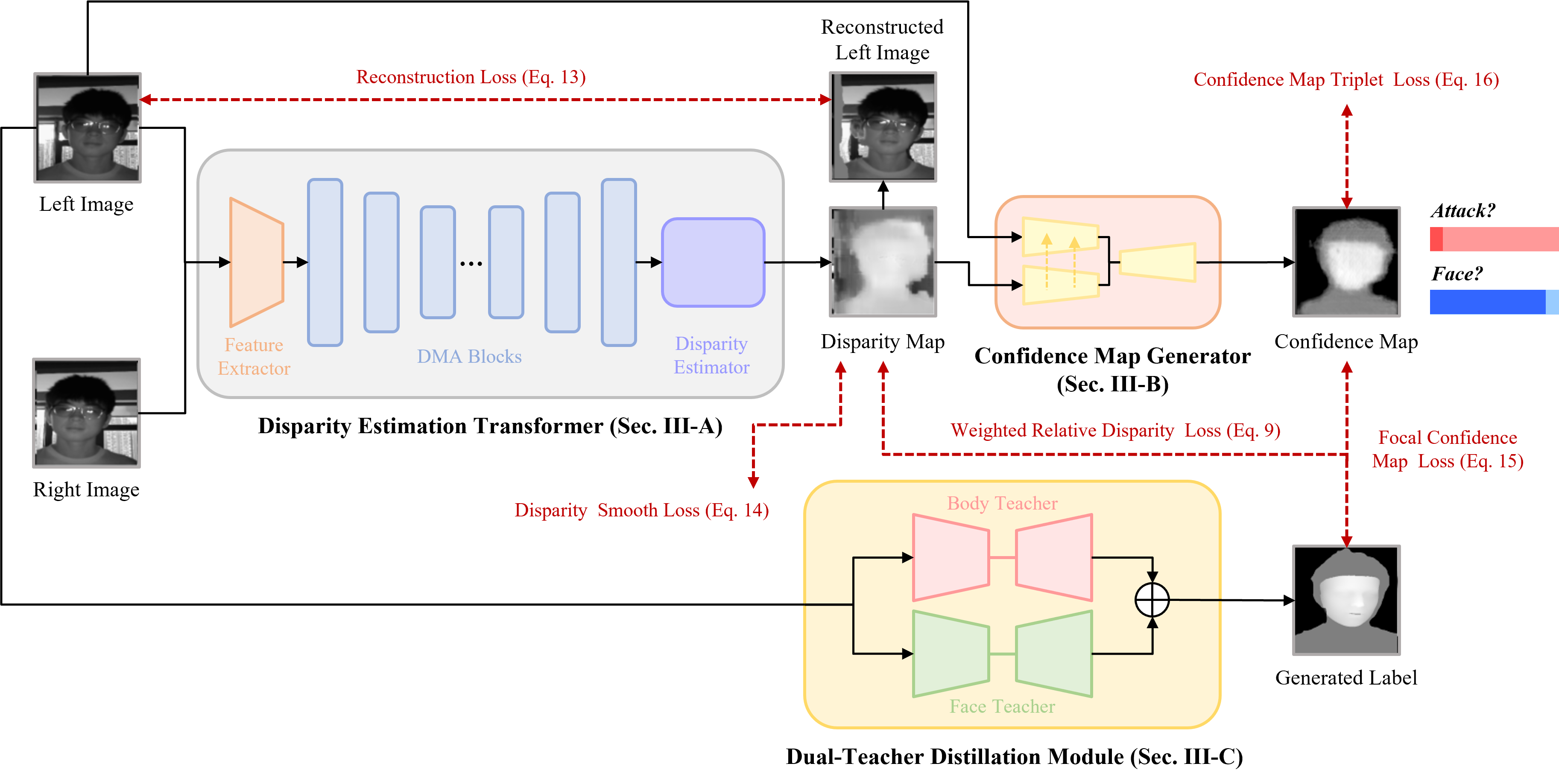
Single-shot face anti-spoofing (FAS) is a key technique for securing face recognition systems, and it requires only static images as input. However, single-shot FAS remains a challenging and under-explored problem due to two main reasons: 1) on the data side, learning FAS from RGB images is largely context-dependent, and single-shot images without additional annotations contain limited semantic information. 2) on the model side, existing single-shot FAS models are infeasible to provide proper evidence for their decisions, and FAS methods based on depth estimation require expensive per-pixel annotations. To address these issues, a large binocular NIR image dataset (BNI-FAS) is constructed and published, which contains more than 300,000 real face and plane attack images, and an Interpretable FAS Transformer (IFAST) is proposed that requires only weak supervision to produce interpretable predictions. Our IFAST can produce pixel-wise disparity maps by the proposed disparity estimation Transformer with Dynamic Matching Attention (DMA) block. Besides, a well-designed confidence map generator is adopted to cooperate with the proposed dual-teacher distillation module to obtain the final discriminant results. The comprehensive experiments show that our IFAST can achieve state-of-the-art results on BNI-FAS, proving the effectiveness of the single-shot FAS based on binocular NIR images.